分布式系统:2.Models of distributed systems
本文最后更新于:2022年3月15日 中午
2. Models of distributed systems
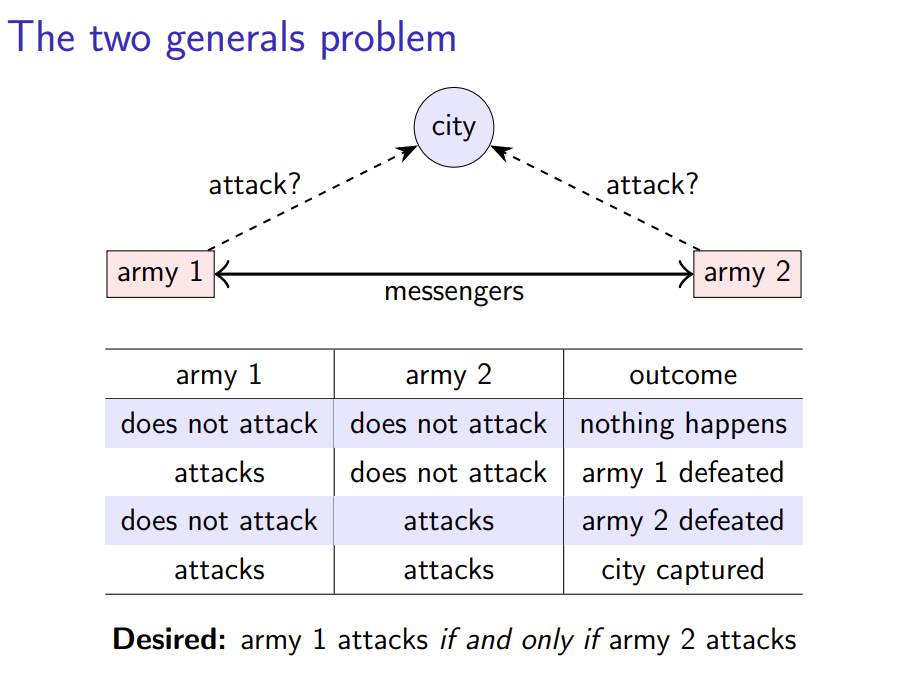
2.1 The two generals problem
应用到在线购物上
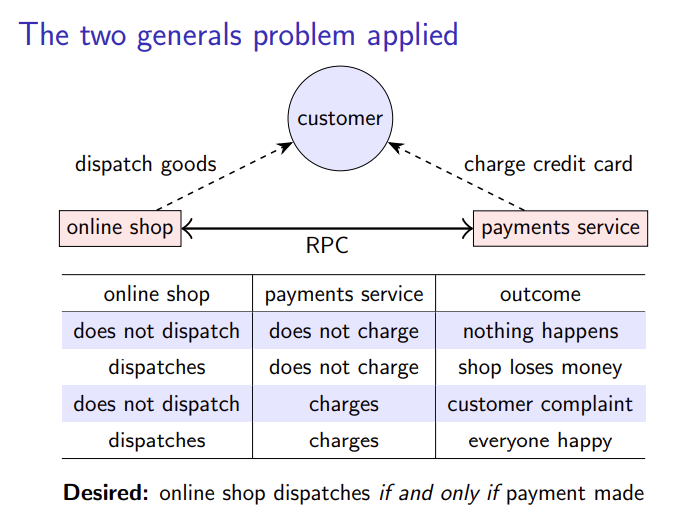
不同的是,这种情况下可以钱可以先打到账上,无论是否发货。支付服务总是进行支付是安全的,因为如果商店如果不能发货,它可以退款。付款是可以撤销的(不像一支军队被击败)使问题得以解决。
类比TCP三次握手
2.2 The Byzantine generals problem
假设信使不会在路上被杀害,但是存在叛徒(恶意malicious),发送欺骗信息
结论:至少需要$3f+1$个结点来允许$f$个结点为恶意节点(恶意结点个数必须严格小于$\frac{1}{3}$)
数字签名和密码学也可以解决问题(但很复杂)
Byzantine fault tolerant 拜占庭容错
2.3 Describing nodes and network behaviour
- 网络:不可靠的、少量丢失的、可靠的
- 结点:拜占庭、崩溃恢复、崩溃停止
- 同步:异步、部分同步(无线时间下同步)、同步(有时间限制)
网络导致不同步问题:
- 消息丢失
- 网络拥堵
- 路由器重新配置
结点导致不同步问题:
- 操作系统调度
- 垃圾回收
- 缺页中断
| 网络模型 | 节点模型 | 时机模型 |
|---|---|---|
| 可靠(reliable):消息一定可达 | 崩溃停止(fair-stop):节点可能崩溃且永远不会恢复 | 同步(synchronous):消息只会延迟有限时间、节点以已知的速度执行 |
| 部分丢失?(fair-loss):消息可能丢失,但有限时间内重新发送一定能达到;(可通过retry达到reliable) | 崩溃恢复(fair-recover):节点可能崩溃但有限时间内能够恢复 | 部分同步(partically-synchronous):大部分情况下是同步,部分情况下是异步 |
| 任意(arbitrary):消息可能被截获;(可通过TLS达到fair-loss) | 拜占庭:节点可能做出欺骗算法的行为 | 异步(asynchronous):消息可能延迟、节点可能暂停,且恢复时间不可知 |
对于真实的分布式环境,一般是崩溃恢复+部分同步。
2.4 Fault tolerance and high availability
服务器24/7运行
| work | fault |
|---|---|
| 99% | down 3.7 days/year |
| 99.9% | down 8.8 hours/year |
| 99.99% | down 53 minutes/year |
| 99.999% | down 5.3 minutes/year |
Service-Level Objective (SLO):服务水平目标
Service-level agreement(SLA):服务水平协议,服务提供方与客户间的协议/合同
高可用:容错
Failure:整个不可用
Fault:系统部分不可用
- 结点crash、偏离算法(拜占庭)
- 网络错误、延迟
错误检测:结点要么错误、要么工作正常
一般错误检测通过超时实现,但无法区分结点到底是crash还是偶尔无响应、网络延迟
只有在绝对可靠的链路(同步系统)中才存在完美的超时错误检测机制,在异步系统中超时检测是没有意义的。
在半同步系统中,采取最终错误检测机制(Eventually perfect failure detector):
- 可能会认为一个结点错误,但是其仍然正常运行
- 可能会认为一个节点正常,但是其以及出错
- 但是最终,只有当一个节点错误的时候才会被认为出错
系统模型可以帮我们评测分布式算法的正确性,如果针对一个系统模型的算法在各种情况下都能满足算法的定义,那么我们可以说这个算法是正确的。
算法的定义即算法的描述,如排序算法的定义可以是对于输出列表的任何两个不同的元素,左边的小于右边的,而对于算法的定义可以区分两种不同的类型,即安全性(safety)和活性(liveness)。
- 安全性:不会给出错误的结果
- 活性:预期的事情最终一定会发生
通常对于分布式算法,要求在所有可能的系统模型下,都不能违反算法的安全性定义。
然而,系统模型只是对现实某部分的简化抽象,例如建立在崩溃恢复模型下的算法处理不了持久性数据被破坏(硬盘故障)的情况。即证明算法正确不意味着真实系统上的某个具体实现一定是正确的。
参考文献
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!